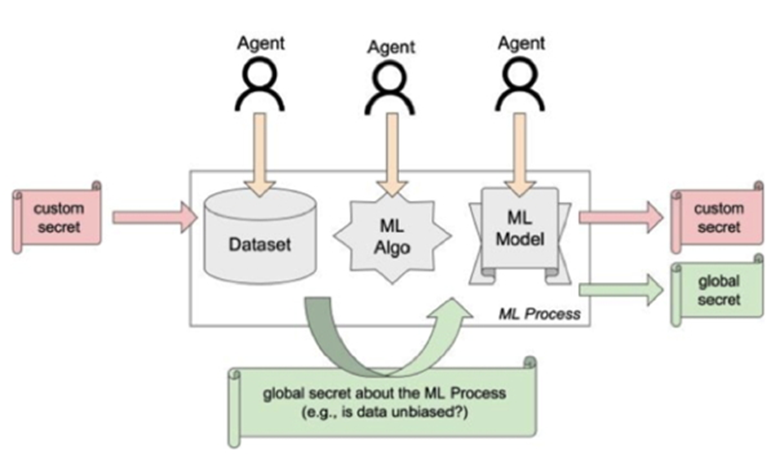
WHAM! recognizes the increasingly important role of the Machine Learning-as-a-service (MLaaS) paradigm, which delegates most of the training pipeline to third parties. In this new context, traditional security assessment techniques covered by Adversarial ML (poisoning, evasion, inversion, or pattern mining attacks) may need to be adapted. WHAM! aims to improve and certify the robustness of artificial intelligence systems throughout the MLaaS pipeline by investigating new schemes for embedding information in ML models at training time for security purposes, with the goal of simplifying model certification at the time of testing. For instance, embedded watermarks to check whether the MLaaS provider has used the submitted dataset in its entirety, or conversely whether the model has been exposed to potential bias.
Some points of interest of the project are
(i) the security implications of information hiding mechanisms when used with AI/ML frameworks;
(ii) the effectiveness of watermarks with respect to their exploitability for malicious campaigns;
(iii) defense mechanisms to prevent exfiltration attacks using watermarks.
Length: 28/09/2023 – 27/09/2025
Project Coordinator: Giuseppe Manco
Founding :PRIN 2022/Decreto PE6 Prot. 959 del 30/06/2023
{kind=link}