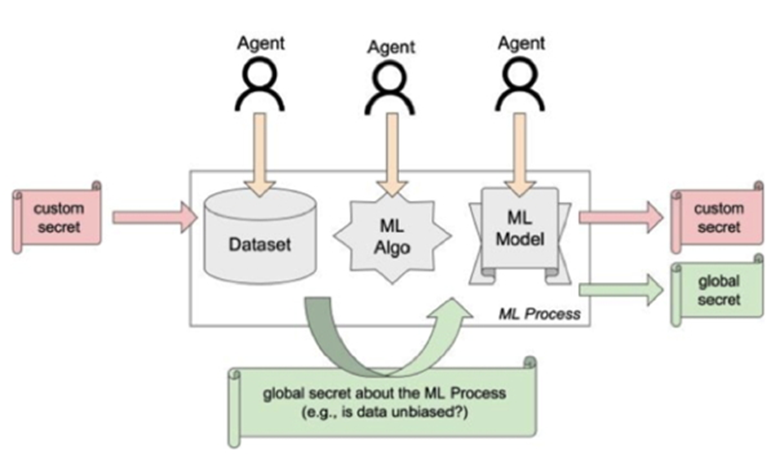
WHAM! riconosce l’importanza crescente del paradigma Machine Learning-as-a-Service (MLaaS), che delega gran parte del processo di addestramento a terze parti. In questo nuovo contesto, le tecniche tradizionali di valutazione della sicurezza, coperte dall’Adversarial Machine Learning (come attacchi di avvelenamento, evasione, inversione o estrazione di pattern), potrebbero dover essere adattate. WHAM! mira a migliorare e certificare la robustezza dei sistemi di intelligenza artificiale lungo l’intera pipeline MLaaS, investigando nuovi schemi per incorporare informazioni nei modelli di machine learning durante la fase di addestramento per scopi di sicurezza, con l’obiettivo di semplificare la certificazione del modello al momento del test. Ad esempio, i watermark integrati potrebbero verificare se il fornitore di MLaaS ha utilizzato l’intero dataset fornito o, al contrario, se il modello è stato esposto a potenziali bias.

Alcuni punti di interesse del progetto sono:
(i) le implicazioni di sicurezza dei meccanismi di nascondimento delle informazioni quando utilizzati con framework AI/ML;
(ii) l’efficacia dei watermark in relazione alla loro sfruttabilità per campagne malevole;
(iii) i meccanismi di difesa per prevenire attacchi di esfiltrazione utilizzando i watermark.
Durata: 28/09/2023 – 27/09/2025
Project Coordinator at ICAR: Giuseppe Manco
Finanziamento: PRIN 2022/Decreto PE6 Prot. 959 del 30/06/2023
{kind=link}